

Цифровой глаз геолога: нейросетевая экспертиза подлинности изображений керна для изысканий

В статье рассматривается алгоритм автоматизации контроля подлинности изображений керна в инженерно-геологических изысканиях. Основной целью разработки является повышение точности и снижение риска ошибок, обусловленных человеческим фактором при ручной проверке фотоматериалов. Предложенный подход включает три последовательных этапа: автоматическое выделение керна на изображениях, формирование уникального цифрового отпечатка с использованием нейронных сетей и выявление дубликатов на основе сравнения визуальных признаков. Результаты производственной апробации демонстрируют высокую эффективность метода: точность обнаружения дубликатов достигает 97%, полнота — 95%. Применение технологии позволяет ускорить процесс проверки изображений более чем в тысячу раз, устранить субъективность оценки и существенно сократить трудозатраты. Метод реализован в виде промышленного программного решения, внедрённого в продукты компаний Soilbox и Digital Petroleum, и готов к масштабированию на крупных проектах с возможностью дополнительной калибровки на корпоративных наборах данных.
Оглавление
3.1 Исходные данные и условия эксперимента
3.2.1. Автоматическое выделение керна на фотографиях
3.2.2. Извлечение «цифрового отпечатка» каждого образца
3.2.3. Поиск похожих образцов и выявление дубликатов
1. Введение
При проведении инженерно-геологических изысканий контроль качества данных по скважинам традиционно основан на ручных процедурах: проверке полевых описаний, фото- и видеоматериалов, сверке геотегов и времени съёмки, сопоставлении изображений с ожидаемым объёмом отобранного керна, а также контроле временных интервалов бурения и полученного материала.
В Soilbox большая часть таких проверок полностью автоматизирована. Для этого валидируются два класса данных.
1. Полевые метаданные, полученные непосредственно с мобильных устройств в момент создания любого объекта в приложении (слои, рейсы, пробы, фото, видео и т. д.), — геотеги, дата/время, устройство.
2. EXIF-метаданные всех фото- и видеоматериалов.
Обе группы данных перекрёстно сверяются алгоритмами с плановым и фактическим положением скважин, а также с временными рядами создания/редактирования всех вложенных объектов внутри скважины. В случае наличия проблем в выработке руководитель работ получает всю информацию о нестыковках, что обеспечивает непрерывный контроль качества данных в режиме онлайн.
Однако остается важная «серая зона» — выявление дублирования и компоновочных фальсификаций фотоматериалов по керну.
Типовая ситуация: последние 5 метров в скважине с проектной глубиной 20 метров «собраны» из фрагментов ранее отснятых 15-ти метров.
Сегодня подобные случаи на крупных объектах выявляются вручную специалистами службы контроля качества. Это не менее двух сотрудников на один объект! Такой подход отнимает значительное время, является весьма дорогостоящим и субъективным.
Технологии CV (Computer Vision) и DL (Deep Learning) позволяют устранить значительную долю субъективности в работе и обеспечить воспроизводимую, измеримую оценку данных. В смежных задачах по анализу изображений керна и литотипов современные CNN (Convolutional Neural Network)-модели стабильно показывают высокую точность: от ~70% на сложных наборах литофаций до ~99.6% на специализированных наборах данных керна [Alzubaidi и др., 2021; Fu и др., 2022; Baraboshkin и др., 2020; Lima и др., 2019].
Современные методы обнаружения манипуляций и повторного использования фрагментов изображений демонстрируют высокую эффективность. В исследованиях последних лет сообщается о точности свыше 90% на контролируемых тестовых наборах. Такой уровень достигается благодаря сочетанию двух ключевых технологий.
1. Трансформеры — класс нейросетевых моделей, изначально разработанных для обработки текста, но впоследствии успешно адаптированных к задаче анализа изображений. Они хорошо улавливают сложные взаимосвязи в данных и позволяют точнее выявлять изменения и подмены фрагментов.
2. Перцептуальные хэши — быстрые алгоритмы, формирующие компактный «отпечаток» изображения. Этот отпечаток позволяет определять схожесть изображений даже при их частичном изменении: сжатии, повороте, кадрировании и других типах искажений.
Совмещение трансформеров и перцептуальных хэшей обеспечивает как высокую скорость обработки данных, так и устойчивость к вариативности внутри фотографий (структур, текстур и пр.) [Amiri, Mosallanejad, Sheikhahmadi, 2024; Liang и др., 2025].
В задачах массовой антидубликатной проверки на практике хорошо зарекомендовал себя двухэтапный каскад:
- выполнение в первую очередь быстрой первичной фильтрации изображений с помощью перцептуального хэша, чтобы отсечь явно несхожие снимки;
- последующее сравнение оставшихся фотографий с использованием глубокой модели вроде CLIP (Contrastive Language–Image Pre-training), которая извлекает из них информативные эмбеддинги — числовые представления, отражающие смысловое содержание каждого элемента. Эти компактные векторные описания позволяют точнее сопоставлять элементы между собой.
Такой подход позволяет обеспечивать высокую скорость и точность: быстро отсеивать нерелевантные варианты и детально анализировать сложные случаи без необходимости переобучать тяжёлые нейросетевые модели (Haq, 2025).
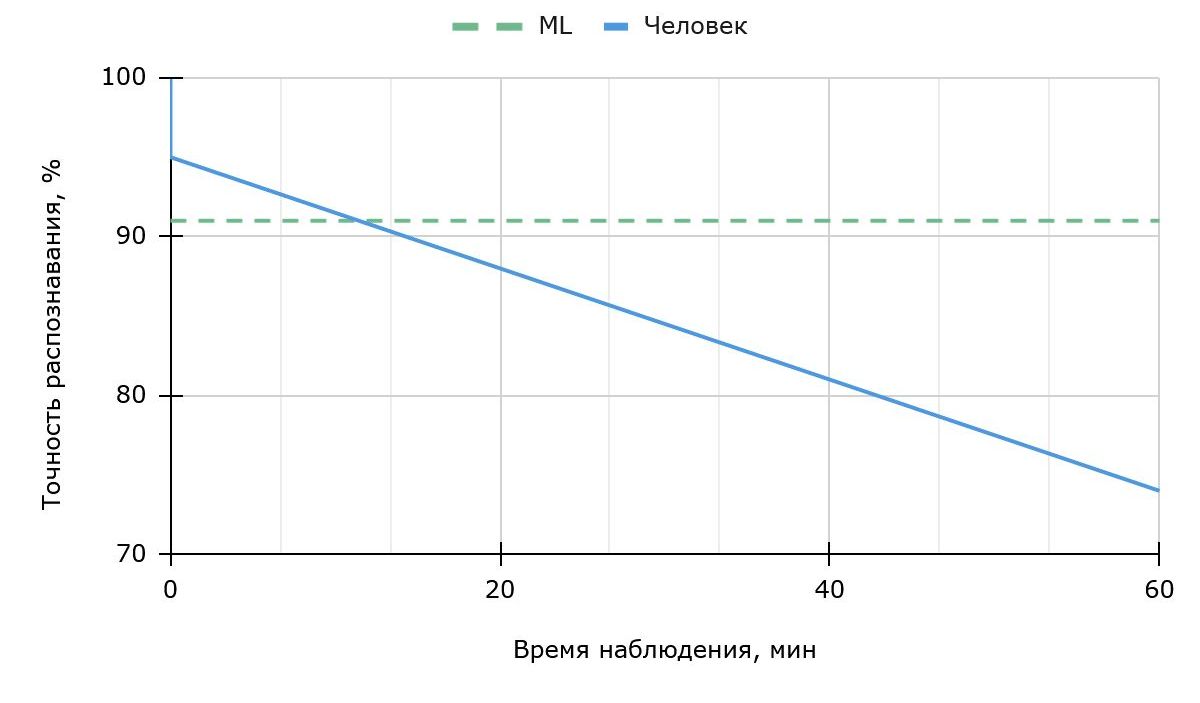
Необходимо отметить, что за последнее десятилетие область компьютерного зрения совершила качественный скачок: точность лучших моделей в эталонных задачах распознавания давно достигла уровня, сравнимого с человеческим, даже при классификации изображений на 1000 классов [Shankar и др., 2020] (рис.1). Ряд исследований показывает, что при длительной непрерывной работе над монотонными задачами, включая визуальное распознавание фотоматериалов, уровень внимания человека к деталям через час снижается в среднем примерно на 20%. [Krupinski, 2010; Langner, Eickhoff, 2013; Parasuraman, Riley, 1997; Warm, Parasuraman, Matthews, 2008]. На основе усреднённых данных о точности визуального распознавания изображений человеком и снижении качества распознавания во времени можно построить график в виде линейной аппроксимации (рис.2).
Это дополнительно подтверждает целесообразность внедрения современных методов обработки изображений в геологические регламенты и системы контроля качества.
![Рис.1. Сравнение точности распознавания изображений на наборах данных ImageNet и ImageNetV2 между алгоритмами машинного обучения и человеком [Shankar и др., 2020, с изменениями]. Указана многоклассовая точность как для свёрточных нейронных сетей (CNN), так и для живых участников на проверочном наборе данных ImageNet в сравнении с их точностью на тестовом наборе ImageNetV2. Показаны 95% доверительные интервалы Клоппера-Пирсона.](/images/dynamic/img59195.jpg)
В этой работе Soilbox и Digital Petroleum представляют подход к автоматизированному выявлению дублирования и компоновочных фальсификаций по фотографиям керна. Методика включает три взаимодополняющих шага.
1. Быстрый поиск подозрительных совпадений с помощью устойчивых перцептуальных признаков, позволяющих мгновенно находить изображения, визуально похожие друг на друга.
2. Уточняющее сравнение за счёт глубоких эмбеддингов, которые детальней описывают содержимое изображений и помогают правильно ранжировать найденные «похожие» пары.
3. Точная проверка на уровне локальных соответствий с учётом специфики реальных условий съёмки керна: ориентации кернов в ящике, повторяющихся природных текстур, особенностей освещения, а также типичных артефактов полевой фотографии. Все эти факторы образуют домен задачи — особенности данных, которые характерны именно для инженерно-геологических работ и требуют отдельного внимания.
Такой комбинированный подход позволяет автоматически просканировать весь массив изображений по скважине, выделить участки с вероятными повторами или перекладками, сформировать отчёт для служб контроля и существенно снизить трудозатраты, повысить производительность и объективность по сравнению с ручной проверкой.
2. Изученность
Автоматизация описания и классификации керна представляет собой один из наиболее динамично развивающихся трендов в современной геологоразведке и нефтегазовой индустрии. При этом авторами не было найдено опубликованных работ для задач в инженерно-геологических изысканиях.
За последнее десятилетие в геологоразведке произошел заметный переход от традиционного ручного описания керна, требующего многочасовой работы опытных геологов, к автоматизированным рабочим процессам, основанным на методах компьютерного зрения и машинного обучения [Baraboshkin и др., 2020; Mezghani, Masrahy, 2020; Solum, Narr, Benson, 2022]. Этот переход обусловлен не только потребностью в ускорении процессов геологического описания, но и необходимостью обеспечения воспроизводимости и объективности интерпретации, особенно при работе с большими объёмами архивных данных и многочисленными скважинами.
Современные исследования охватывают широкий спектр задач: от фациальной классификации и сегментации геологических структур до автоматического расчёта индексов качества керна (RQD) и оценки состояния архивных коллекций [Fellgett и др., 2022; Xu и др., 2023]. Особое внимание уделяется интеграции визуальных данных с петрофизическими измерениями, геохимическими анализами и результатами лабораторных испытаний, что позволяет создавать комплексные модели предсказания свойств горных пород непосредственно по изображениям керна [Boiger и др., 2024; Starbuck, 2022]. Они решаются как традиционными подходами глубокого зрения, так и более современными на основе механизма внимания (attention mechanism), когда внутри находится специальный блок, подсвечивающий важные характеристики [Koeshidayatullah и др., 2022].
При проектировании систем автоматизированной обработки изображений керна критически важно учитывать условия съёмки, однородность разметки и методы валидации на независимых скважинах, поскольку большинство современных моделей демонстрирует чувствительность к вариациям в освещении, качеству фотографий и наличию маркеров на образцах [Shvalyuk и др., 2025].
Несмотря на впечатляющий прогресс в автоматизации анализа снимков керна проблема обнаружения дубликатов изображений и фальсификации данных остаётся практически неисследованной. Проведённый систематический обзор более 150 публикаций из ведущих научных баз данных (SciSpace, Google Scholar, PubMed, Web of Science, Scopus, ArXiv) за 2018–2025 годы не выявил ни одного исследования, предлагающего валидированную методологию автоматической детекции преднамеренных дубликатов или подмены ранее задокументированного керна.
Полученные результаты во многом объясняются особенностями отечественной практики инженерно-геологических изысканий. В России проблема контроля подлинности и полноты кернового материала стоит значительно острее, чем за рубежом. В «большой» геологии весь керн, как правило, отбирается полностью и передаётся в специализированные центры хранения и документирования, что минимизирует риск искажений. В инженерных изысканиях ситуация иная. Здесь официальным документом является полевой журнал, заполняемый геологом, тогда как фотография выступает лишь подтверждающим материалом, а не первичным источником данных. Такой подход создаёт больше возможностей для непреднамеренных ошибок и умышленных манипуляций, что делает задачу автоматизации контроля особенно актуальной именно в области инженерно-геологических изысканий.
Хотя специализированных исследований по детекции дубликатов керна не существует, ряд работ содержит технические компоненты, которые потенциально применимы для решения этой задачи. [Starbuck, 2022] отмечал, что присутствие повторных снимков одного и того же интервала керна с различными маркерами или в разных условиях освещения может существенно искажать обучение моделей и приводить к завышенным оценкам точности. Автоматическое выявление и удаление таких дубликатов из обучающей выборки улучшило метрики классификации и уменьшило риск переобучения модели.
Системы контроля качества, такие как разработанная [Shvalyuk и др., 2025], способны автоматически выявлять изображения с нестандартными характеристиками (необычное освещение, посторонние объекты, искажения цвета), что косвенно может указывать на манипуляции с данными. Однако эти системы не предназначены специально для детекции преднамеренной фальсификации и не могут обнаруживать случаи, когда одно и то же изображение керна представлено как происходящее из разных скважин или глубин.
Перспективным направлением представляется применение перцептуальных хэш-функций (perceptual hashing) и методов поиска визуально схожих изображений для выявления потенциальных дубликатов в больших базах данных керна. Комбинация визуального анализа с проверкой метаданных (глубина отбора, дата съёмки, идентификатор скважины) может обеспечить надёжное определение как случайных дублирований, так и преднамеренных фальсификаций.
3. Технология
3.1 Исходные данные и условия эксперимента
Все исходные данные были получены от нескольких инженерно-геологических компаний и отражают реальные условия на различных объектах. В выборку вошли образцы грунтов разных типов — преимущественно дисперсных, а также полускальных.
Для создания основной части выборки керна с дубликатами был воспроизведён процесс перекладки керна, характерный для полевых инженерно-геологических изысканий. Перекладку выполняли геологи, участвовавшие в исходной съёмке и хорошо знавшие реальное расположение образцов. При этом учитывались возможные повороты и вращения керна. Такой подход позволил контролировать истинное положение керна в разрезе и использовать эти данные при оценке точности алгоритма, обеспечивая при этом объективность результатов. Также использовались реально выявленные случаи перекладки керна из инженерно-геологической практики.
Всего для тестирования алгоритма использовалось 120 фотографий керна, из которых 60 изображений соответствовало случаям дублирования керна, а 60 – отсутствию дублей; 40 изображений было получено в результате умышленной перекладки керна для целей тестирования; 20 отобрано из реальных примеров фальсификации данных. Таким образом, тестовая выборка была полностью сбалансирована, что исключало систематическое смещение при оценке качества работы алгоритма.
|
Типы фото |
Количество пар |
Количество в выборке |
Всего |
|
|
Фото с дублированием керна |
Реальные |
10 |
20 |
60 |
|
Имитированные |
20 |
40 |
||
|
Фото без дублирования керна |
30 |
60 |
60 |
|
Таблица 1. Объём данных, использованных в работе
Съёмка проводилась в полевых условиях. Разрешение изображений в основном намеренно ограничивалось форматом HD, чтобы оценить устойчивость работы алгоритма с материалами, полученными с низкомегапиксельных камер. На представленных ниже фото (рис.3 и 4) приведено типовое различие качества, цветовых характеристик, освещения и углов съёмки, формата керновых ящиков.


Краткая статистика по изображениям
• Всего изображений: 120
• Форматы: JPEG 100%
• Цветовые режимы: RGB 100%
• Ширина: 607–4284 px (мед. 810)
• Высота: 642–5712 px (мед. 1080)
• Мегапиксели: 0.57–24.47 MP (мед. 0.88 MP)
• DPI в метаданных: 77%, медиана 96Ч96 dpi
• JPEG: прогрессивные 40%, качество мед. 41 (диап. 20–91)
В связи с тем, что фотофиксация до сих пор слабо поддаётся стандартизации даже внутри одной организации, набор данных был сформирован с учётом различных условий освещения, устройств съёмки, экспозиции, углов наклона и типов керновых ящиков. Это позволило оценить универсальность модели и адаптировать её к разнообразию условий получения данных по фотоматериалам инженерно-геологических изысканий.
Разработанная система состоит из трёх основных компонентов, которые работают последовательно.
3.2.1. Автоматическое выделение керна на фотографиях
Задача. Найти на фотографии керновых ящиков только сам керн, исключив всё лишнее — фон, маркеры глубины, этикетки, тени, блики.
Решение. Используем алгоритм автоматической сегментации из научной работы [Baraboshkin и др., 2022] (рис.5). Дополнительно происходит автоматическая увязка керна по глубине.


Что делает алгоритм. Автоматически находит и вырезает области с керном (ROI — regions of interest), убирает пустые ячейки, упаковочные материалы, технические элементы, исключает маркеры, этикетки, метрические шкалы, определяет границы между отдельными фрагментами керна.
Результат. Для каждого фото керна создаётся набор изображений отдельных фрагментов с метаданными (скважина, глубина, изображение).
3.2.2. Извлечение «цифрового отпечатка» каждого образца
Задача. Создать для каждого фрагмента керна уникальное числовое описание — вектор признаков, который кодирует его визуальные характеристики (текстуру, цвет, структуру, паттерны).
Решение. Используем ансамбль предобученных нейронных сетей (CNN), которые уже умеют распознавать типы пород, текстуры и структуры керна.
Ключевое преимущество. Система не требует дополнительного обучения на датасете размеченных дубликатов, поскольку работает на предобученных алгоритмах. Это критически важно, поскольку таких датасетов просто не существует. Создание размеченной базы дубликатов керна потребовало бы огромных затрат времени и экспертизы.
Как это работает. Используется несколько предобученных моделей (ResNet, EfficientNet и специализированные модели для геологических данных). Каждая модель обрабатывает изображение керна и извлекает признаки из своих внутренних слоёв. Признаки от всех моделей объединяются в общий вектор. Вектор нормализуется. Это делает сравнение более точным и быстрым.
Технические детали. Решение реализовано на библиотеке PyTorch, работает эффективно на процессоре для быстрой обработки больших объёмов данных. Итоговый вектор признаков имеет размерность до 2048-ми чисел. Каждое число кодирует определённую визуальную характеристику образца.
Аналогично отпечаткам пальцев каждый образец керна получает свой уникальный «цифровой отпечаток», который потом можно быстро сравнивать с другими.
3.2.3. Поиск похожих образцов и выявление дубликатов
Задача. Найти в базе данных все пары изображений керна, которые выглядят подозрительно похожими.
Решение. Используем метрику косинусного сходства — математический способ измерения, сходимости «цифровых отпечатков».
Формула косинусного сходства
similarity(v1, v2) = (v1 · v2) / (||v1|| Ч ||v2||)
где v1 и v2 — векторы признаков двух изображений керна
Что означают индексы
1.0 — изображения идентичны
0.9–0.99 — очень высокое сходство (подозрение на дубликат)
0.7–0.89 — заметное сходство (возможно, керн из одного интервала)
< 0.7 — разные образцы.
Почему применяется косинусное сходство. Оно не зависит от абсолютной величины векторов — важен только «угол» между ними. Очень быстро вычисляется (важно для больших баз данных). Легко интерпретировать — значения от -1 до 1.
Алгоритм определения
1. Загрузка изображений керна.
2. Извлечение «цифрового отпечатка» (вектор признаков).
3. Сравнение со всеми изображениями в базе данных.
4. Сортировка результатов по степени сходства.
5. Отбор пар с высоким сходством (> 0.9).
6. Проверка метаданных: высокое визуальное сходство при несовместимых метаданных — подозрительный случай.
7. Создание отчёта с парами подозрительных изображений для экспертной проверки.
4. Результаты
Разработанный подход отличается простотой внедрения, поскольку не требует дополнительного обучения моделей. Вместо этого используются готовые предобученные алгоритмы, обеспечивающие извлечение ключевых признаков изображений керна. Такой подход позволяет использовать весь доступный объём данных в качестве тестового набора без необходимости разделения на обучающую и валидационную выборки.
Основные показатели эффективности
Точность (precision) — доля верно обнаруженных случаев среди всех отмеченных системой как положительные. Показатель составил 97%, что, согласно ранее приведённым данным (рис.2), сопоставимо, а при больших объёмах превосходит человеческие возможности. Пока нет возможности сравнить показатель с другими автоматизированными подходами, поскольку он является уникальным. В дальнейшем, при появлении возможности и желания заказчиков можно будет провести аналогичный [Shankar и др., 2020] эксперимент для сравнения точности разных экспертов и подходов.
Полнота (recall) — процент реально присутствующих нарушений, которые были обнаружены системой. Значение близко к максимуму, что демонстрирует хорошую чувствительность алгоритма. Показатель составил 95%.
Оптимизация порога схожести позволила добиться баланса между этими двумя показателями, сведя к минимуму влияние человеческого участия и снизив риск возникновения ошибок. Варьируя величину порога и отслеживая изменения показателей точности и полноты, можно подобрать оптимальный показатель порога. Было найдено такое значение, которое обеспечило максимальную эффективность обнаружения дубликатов при минимальном количестве ошибок. В итоге был найден порог, позволяющий:
- обнаружить подавляющее большинство реальных дубликатов (полнота близка к максимальной);
- практически исключить вмешательство человека в процесс анализа (за счёт автоматизации принятия решений);
- минимизировать риски ложных срабатываний и пропустить минимальное количество подлинных дубликатов;
- выявить 29 из 30 фальсификаций.
В зависимости от потребностей конечного пользователя и типа данных порог может быть дополнительно настроен. Но в общем случае его можно применять «как есть».
Практический результат
На экспериментальной выборке из 60 пар изображений система смогла обнаружить 29 фальсификаций из имеющихся 30, зафиксировав при этом единственное ложноположительное срабатывание (рис.6).
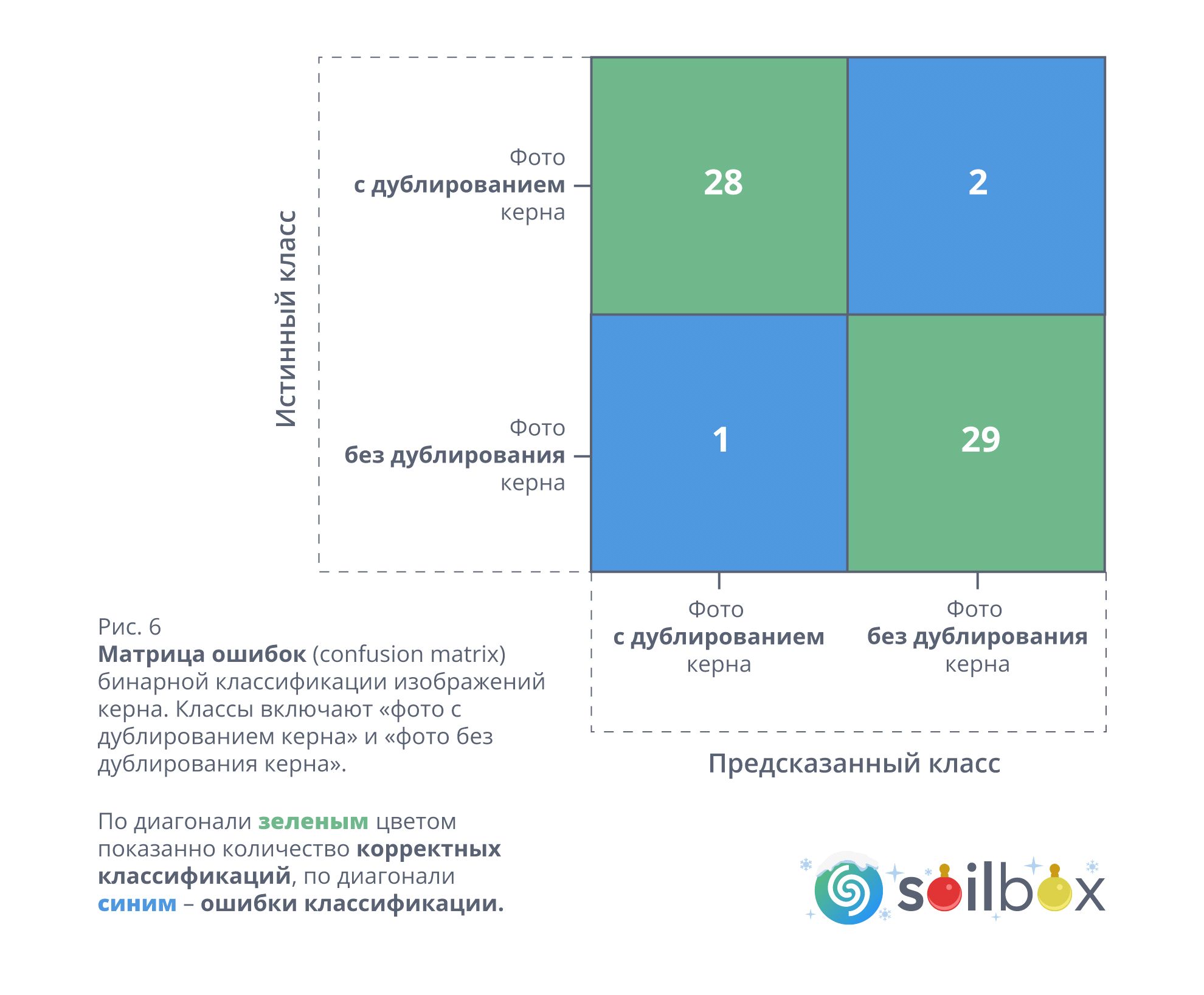
Общая точность классификации составила 95% при значениях precision, recall и F1-score близких к 0.95 для обоих классов, что свидетельствует о стабильности и надёжности методики (таблица 2).
|
Класс |
Класс |
Recall |
F1-score |
Support |
|
Фото с дублированием керна |
0.97 |
0.93 |
0.95 |
30 |
|
Фото без дублирования керна |
0.94 |
0.97 |
0.95 |
30 |
|
Среднее (macro avg) |
0.95 |
0.95 |
0.95 |
60 |
Таблица 2. Метрики качества классификации
Дополнительные преимущества
- Высокая устойчивость алгоритма к изменению условий съёмки (освещения, углов обзора).
- Низкий уровень ложных срабатываний — менее 5%.
- Быстрая обработка данных: серия фотографий по одной скважине обрабатывается приблизительно за одну минуту.
Эти особенности свидетельствуют о высокой эффективности и практичности предлагаемого подхода, делая его отличным инструментом для автоматического выявления фальсификаций и дубликатов изображений керна.
В результате работы алгоритма при анализе пар изображений выявляются фрагменты керна с потенциальными дубликатами (рис.7). Поскольку для одной и той же области по ряду причин может быть найдено несколько соответствий (например, из-за сходства текстур и других визуальных характеристик в пределах одного разреза или в случаях разрушенного керна), на изображениях слева отмечаются участки в виде прямоугольных полигонов с уникальными id, для которых допускается наличие дубликатов, а на изображениях справа — их наиболее вероятные соответствия с указанием одноимённого id с первого изображения и дополнительным номером.

5. Выводы
Разработанный алгоритм обеспечивает полное автоматическое сканирование керна по всей длине скважины, позволяя выявлять повторяющиеся участки даже при их размещении в разных интервалах.
Система распознаёт факты перекладки керна, включая случаи, когда отдельные образцы были перевёрнуты, перемещены или частично заменены.
Анализ проводится на основе сравнения текстурных и структурных характеристик каждого интервала, что обеспечивает высокую точность определения дубликатов и несоответствий.
Такой подход ускоряет процесс проверки фотоматериалов более чем в 1000 раз по сравнению с ручной проверкой и позволяет полностью исключить человеческий фактор — система не подвержена снижению концентрации внимания, усталости и субъективным оценкам.
Экономический эффект применения системы выражается в снижении трудозатрат службы контроля качества за счёт автоматизации ручной сверки фотографий керновых ящиков, что позволяет высвободить рабочее время не менее двух специалистов на одном объекте. Это создаёт возможность перераспределения ресурсов на другие задачи или одновременное ведение нескольких крупных объектов. Дополнительно система позволяет выявлять скрытые случаи фальсификаций, трудноопределимые при визуальной оценке человеком.
Несмотря на то, что система не требует дообучения, возможна её калибровка на корпоративных наборах данных заказчика для достижения точности близкой к 100% в сложных и уникальных сценариях.
6. Заключение
В работе представлена успешно апробированная методика нейросетевой экспертизы подлинности изображений керна для инженерно-геологических изысканий, основанная на применении алгоритмов компьютерного зрения и машинного обучения. Предложенный подход позволяет рассматривать геологический материал не только как набор фотографий, но как цифровое представление керна, пригодное для автоматизированного анализа.
Методика реализована в виде программного модуля и успешно внедрена в программную платформу Soilbox при участии Digital Petroleum. Результаты апробации на реальных производственных данных подтверждают её применимость и готовность к промышленному тиражированию на крупных объектах при проведении инженерно-геологических изысканий.
Использование подобных решений способствует повышению качества, воспроизводимости и достоверности первичных инженерно-геологических данных, формируя основу для перехода отрасли к цифровым стандартам нового поколения и data-driven-подходам в геологии.
7. Примечания
Soilbox – аккредитованная ИТ компания, резидент «Сколково» и Московского инновационного кластера. Разрабатывает цифровые инструменты для автоматизации процессов сбора, хранения и обработки данных в проектно-изыскательской отрасли. Технологии компании обеспечивают комплексное управление и контроль полевых изыскательских работ, позволяя отслеживать данные на всех этапах — от бурения скважин до формирования итоговой отчётности и передачи данных заказчику в цифровом виде, включая возможность работы в режиме реального времени.
Digital Petroleum – ИТ компания. С 2016 года разрабатывала решения в области анализа данных в геологии (включая томографические и временные) как лаборатория в Сколтехе. С 2018 года начала работать с изображениями керна, развивая различные методы анализа фотографий, в том числе отдельные методы компьютерного зрения и глубокого обучения. В 2019 году оформилась как самостоятельная компания и выпустила ряд продуктов на основе своих разработок, включая продукт DeepCore для автоматического анализа изображений керна.
8. Благодарности
Благодарим А. М. Яицкую за создание красочных иллюстраций, а также наших друзей и коллег за участие в обсуждении, критические замечания и предложенные дополнения, без которых наше исследование не было бы полным: А. К. Гладышева (АО «Концерн ВКО «Алмаз-Антей»), Е. А. Сафарову (ФГБУН ИПНГ РАН), Д. С. Савченко (ФГБУН ИГЭ РАН), М. А. Булатникова (МГУ им. М. В. Ломоносова), весь состав команды Digital Petroleum и Soilbox.
9. Krupinski E. A. Current perspectives in medical image perception // Atten. Percept. Psychophys. 2010. Т. 72. № 5. С. 1205–1217.
10. Langner R., Eickhoff S. B. Sustaining attention to simple tasks: A meta-analytic review of the neural mechanisms of vigilant attention. // Psychol. Bull. 2013. Т. 139. № 4. С. 870–900.
12. Lima R. P. de и др. Convolutional neural networks as aid in core lithofacies classification // http://www.seg.org/interpretation. 2019. Т. 7. № 3. С. SF27–SF40.
14. Parasuraman R., Riley V. Humans and Automation: Use, Misuse, Disuse, Abuse // Hum. Factors J. Hum. Factors Ergon. Soc. 1997. Т. 39. № 2. С. 230–253.
15. Shankar V. и др. Evaluating Machine Accuracy on ImageNet // Proceedings of the 37th International Conference on Machine Learning. : PMLR, 2020. С. 8634–8644.
17. Solum J. G., Narr W., Benson R. Accelerating core characterization and interpretation through deep learning with an application to legacy data sets // Interpretation. 2022. Т. 10. № 3. С. SE71–SE85.
19. Warm J., Parasuraman R., Matthews G. Vigilance Requires Hard Mental Work and Is Stressful // Hum. Factors. 2008. Т. 50. С. 433–41.
20. Xu S. и др. Intelligent recognition of drill cores and automatic RQD analytics based on deep learning // Acta Geotech. 2023. Т. 19. С. 2313–2329.
Журнал остается бесплатным и продолжает развиваться.
Нам очень нужна поддержка читателей.
Поддержите нас один раз за год
Поддерживайте нас каждый месяц













